Perché la statistica non ha previsto Trump
Nate Silver – giornalista ed esperto di dati e sondaggi – ha spiegato perché su Trump si è sbagliato come un opinionista qualsiasi
- Condividi
- X
- Regala il Post

Nate Silver, noto giornalista e statistico americano ha scritto sul sito di news FiveThirtyEight, che ha fondato e che dirige, un lungo articolo in cui spiega i motivi per cui non è riuscito a prevedere la nomination di Donald Trump a candidato presidente per i Repubblicani. L’opinione di Silver è particolarmente rilevante perché alcuni anni fa è diventato famoso tra le altre cose per aver inventato un algoritmo che – utilizzando insieme i sondaggi politici e altri dati molto diversi tra loro – ha previsto praticamente stato per stato i risultati delle elezioni statunitensi del 2008 e 2012.
Trump è stato un candidato anomalo: non si era mai interessato davvero di politica, ha una visione del mondo tutta sua e difficilmente inquadrabile nella “destra classica”, e ancora oggi ha buona parte del partito contro. All’inizio delle primarie la stragrande maggioranza dei giornalisti e commentatori americani – anche quelli di solito esperti, affidabili, prudenti – ritenevano che la sua candidatura si sarebbe sgonfiata di lì a breve, citando gli esempi di altre candidature effimere di questi anni che avevano avuto una breve ascesa (l’improbabile proprietario di una catena di pizzerie Herman Cain, o ancora Howard Dean, esperto governatura Democratico la cui candidatura si sbriciolò dopo un goffo grido in un comizio). In questi mesi, mentre Trump vinceva alle primarie stato dopo stato fino a ottenere la candidatura dei Repubblicani, diversi giornalisti americani si sono sentiti in dovere di scusarsi – o comunque di spiegare meglio le proprie ragioni – per aver sottovalutato o preso in giro la sua candidatura.
La posizione di Nate Silver, articolata in cinque parti, è leggermente diversa e un po’ più sfumata: e risente del fatto che Silver ha sempre criticato gli opinionisti in quanto tali, accusandoli di pontificare senza dar retta ai dati, e invece stavolta si è trovato smentito come un opinionista qualsiasi. Semplificando, Silver dice: i dati esistenti su Trump e in generale sulle primarie dei Repubblicani sono diversissimi e difficili da mettere insieme in un unico modello statistico (anche perché ogni elezione influenza l’esito di quella successiva); basandosi sugli scarsi modelli matematici a disposizione Trump era effettivamente dato per sfavorito, ma aveva sicuramente più possibilità di quelle che gli sono state attribuite nei primi mesi; la nomination di Trump insomma era effettivamente poco prevedibile, ma diversi indicatori hanno funzionato più di altri, e forse possono insegnare qualcosa su come occuparsi di altre candidature del genere in futuro.
1. L’assenza di un modello statistico adeguato
Silver spiega che FiveThirtyEight, che è nato con l’ambizione di mescolare giornalismo e metodi scientifici come statistica e teoria delle probabilità, nell’occuparsi di Trump ha seguito la stessa traiettoria dei giornali più istituzionali, che Silver critica spesso perché a suo dire fanno eccessivo affidamento alle analisi politiche “di pancia”, senza il supporto di dati. Ad agosto del 2015 lo stesso Silver aveva stimato un po’ scherzosamente al 2 per cento la probabilità che Trump ottenesse la nomination. Nei mesi successivi la percentuale salì di poco, arrivando attorno al 12-13 per cento all’inizio di gennaio, a poche settimane dalle primarie in Iowa. Dopo la vittoria di Trump in New Hampshire, FiveThirtyEight aumentò la stima arrivando al 45-50 per cento, in linea con le previsioni di quel momento degli scommettitori. Dopo la netta vittoria di Trump in South Carolina, FiveThirtyEight si è allineato agli altri giornali nel prevedere che Trump avrebbe effettivamente ottenuto la candidatura.
Silver si spiega questo andamento col fatto che al contrario di altre elezioni, FiveThirtyEight non aveva preparato nessun modello statistico per prevedere l’esito delle primarie Repubblicane. Spiega Silver:
Il mio ragionamento è stato questo: i modelli statistici funzionano quando hai molti dati a disposizione e quando il sistema che stai studiando ha un livello di complessità strutturale relativamente basso. Il processo di selezione per le primarie non rispetta nessuno dei due criteri: dal punto di vista dei dati si può tornare indietro solo al 1972, la data in cui venne applicato per la prima volta un regolamento delle primarie simile a quello odierno (e i dati sui primi anni sono comunque scarsi). Il sistema che assegna la nomination, inoltre, è uno dei più complessi che io abbia mai studiato: di norma si presentano diversi candidati, e di conseguenza alcune scelte binarie [come “Repubblicano” e “Democratico”, quando si tratta di elezioni generali] in questo caso non si applicano. E dato che le primarie si svolgono uno stato dopo l’altro, ciascuna di esse influenza quelle che vengono dopo. A rendere le cose ancora più complicate, c’è il fatto che le regole con cui si assegnano i delegati sono complesse, specialmente per i Repubblicani, e possono cambiare di anno in anno e di stato in stato.
Silver ammette di essersi pentito di non aver messo a punto un modello statistico apposito, per quanto potesse risultare fallace e poco indicativo. Un modello del genere avrebbe comunque permesso di inquadrare meglio alcuni dati senza affidarsi al caso o alle impressioni personali: e nel corso delle elezioni, complice il ritiro di alcuni candidati e il chiarimento di alcune tendenze di voto nell’elettorato Repubblicano, questo ipotetico modello si sarebbe affinato diventando sempre più preciso. Ammette Silver: «in assenza di un modello, sono stato soggetto agli stessi errori di cui accuso gli opinionisti tradizionali: mi sono intestardito sulle mie previsioni iniziali, e sono stato troppo lento ad aggiornarle tenendo conto dei nuovi dati. Mi sono anche ritrovato a scegliere selettivamente dati e informazioni sulla base di riflessioni pregresse, traendone conclusioni pigre».
2. Se anche avessimo avuto un modello, non avremmo avuto modo di verificarlo
Silver fa notare però che se anche avesse sviluppato un modello apposito per queste elezioni primarie, difficilmente lo si sarebbe potuto “aggiustare” con la calibrazione, uno strumento statistico che permette di migliorare l’accuratezza di un modello sulla base di risultati già ottenuti.
Per spiegarsi meglio Silver cita un esempio tratto dal modello statistico utilizzato da FiveThirtyEight per prevedere l’esito di ciascuna elezione primaria in ognuno degli stati che ha votato finora. Il modello di FiveThirtyEight assegnava a Bernie Sanders, il candidato più “di sinistra” delle primarie Democratiche, meno dell’1 per cento delle probabilità di vincere le primarie del Michigan, che si sono tenute l’8 marzo. Alla fine Sanders ha vinto staccando Clinton dello 0,4 per cento dei voti, e FiveThirtyEight fu molto preso in giro. A prima vista, il loro modello aveva preso una cantonata: in realtà, mettendo in fila le precedenti previsioni in queste primarie sia sui Repubblicani sia sui Democratici, fra i 93 candidati a cui il modello ha assegnato meno del 4 per cento di possibilità di vincere, solo uno di loro ha effettivamente vinto: Bernie Sanders, in Michigan. Ribaltando le cifre: se un candidato ha il 99 per cento di vincere in 100 elezioni diverse, e si sottopone effettivamente a 100 elezioni, se il suo avversario vince una delle 100 elezioni non si può sostenere che il modello abbia sbagliato. Anzi: il modello ha funzionato.
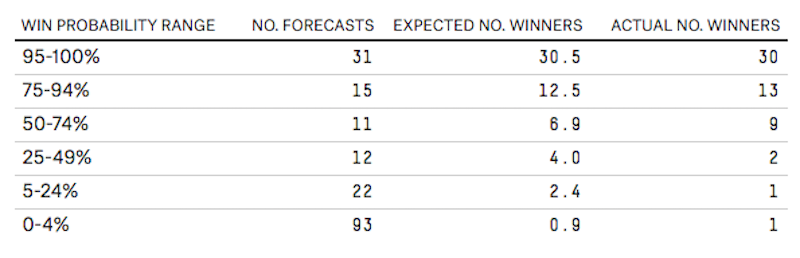
Tutto questo per dire che anche un eventuale modello per prevedere il vincitore della nomination non avrebbe potuto essere “calibrato” con altri modelli precedenti, per le stesse ragioni di prima: troppi pochi dati a disposizione, troppo diversi fra loro. Per esempio: sarebbe stato “poco ortodosso”, dice Silver, calibrare un eventuale modello per le primarie Repubblicane con le centinaia di modelli studiati per altri tipi di elezioni, tutte diverse fra loro.
3. Trump non era favorito, ma le percentuali che gli sono state assegnate erano troppo basse
All’inizio delle primarie circolavano varie stime percentuali – compresa quella di Nate Silver – sulla possibilità che Trump ottenesse la nomination: tutte molto basse, e generalmente inferiori al 10 per cento. Oggi Silver sostiene che anche quelle stime erano troppo basse, sulla base di un semplice calcolo delle probabilità.
Silver sostiene che nel recente passato alle elezioni primarie – sia dei Repubblicani sia dei Democratici – si sono presentati sei candidati paragonabili a Trump: «gente che godeva di scarso appoggio del partito ma che per un certo periodo ha dominato i sondaggi nazionali, a volte sulla base della propria fama». Fra i nomi più noti in questa lista ci sono anche Herman Cain e Jesse Jackson, attivista e predicatore nero che si candidò coi Democratici nel 1987. In nessuno dei sei precedenti individuati da Silver – otto, se si contano anche i casi di Howard Dean e dell’ex sindaco di New York Rudy Giuliani, che si candidò coi Repubblicani nel 2007 – quei candidati hanno ottenuto la nomination. Se non avessimo nessun dato a nostra disposizione e volessimo calcolare la percentuale di vittoria di un nuovo candidato del genere – cioè Trump – potremmo utilizzare una formula del calcolo delle probabilità previste dalle teorie dello statistico Thomas Bayes.
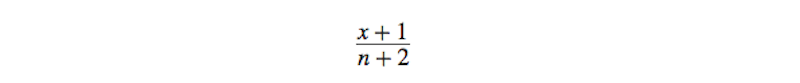
In una formula dove n è il numero dei casi osservati e x le volte in cui un certo fatto è davvero accaduto, dovremmo riempire la formula in questo modo: 0 (cioè le volte in cui ha vinto un candidato simil-Trump) + 1, fratto 6 oppure 8 (a seconda se consideriamo o meno Dean e Giuliani) + 2. Se consideriamo solo 6 casi, un nuovo candidato simil-Trump ha una possibilità su otto di vincere (cioè il 12,5 per cento), mentre se consideriamo 8 casi il rapporto scende a 1 su 10 (cioè il dieci per cento). In ogni caso stiamo parlando di percentuali più alte di quelle assegnate a Trump nei mesi iniziali. Ovviamente si tratta di una formula astratta: Silver però sottolinea che in base a questa e al fatto che avevamo così pochi dati a disposizione, «se decidi di assegnare a Trump meno del 10 per cento delle possibilità di vincere, devi avere delle ottime ragioni per farlo».
4. Dobbiamo rivalutare i sondaggi?
I sondaggi elettorali sono storicamente guardati con un certo scetticismo, soprattutto durante le primarie. A ben guardare, però, quest’anno Trump è stato in cima ai sondaggi più o meno dall’inizio, e i modelli statistici basati solamente sui sondaggi hanno spesso azzeccato il risultato delle varie primarie tenute finora. Secondo Silver questo ci dovrebbe convincere a tenere in minore considerazione le previsioni “aggiustate”, che cioè combinano sondaggi con vari indicatori fra cui il contesto politico e le condizioni economiche del paese: Silver spiega che mentre la scienza dei sondaggi si è in qualche modo evoluta negli ultimi anni, quella delle previsioni “aggiustate” non è riuscita a fare altrettanto da quando si è diffusa, all’inizio degli anni Novanta (anche su FiveThirtyEight le previsioni sui singoli stati che hanno tenuto conto solamente dei sondaggi si sono rivelate un filo più precise di quelle “aggiustate”).
Nel 2000 molte previsioni che mischiavano sondaggi e altri indicatori davano per certa la vittoria di Al Gore contro George W. Bush; otto anni dopo uno di questi modelli previde che Obama avrebbe vinto di 16 punti (un distacco enorme, che poi non si è verificato), un altro che McCain avrebbe vinto di 7 punti. Nel 2012 questi modelli se la sono cavata abbastanza bene, ma uno dei più importanti aveva previsto invece una larga vittoria di Mitt Romney.
Silver spiega che la sua è semplice diffidenza, e che le previsioni di questo tipo rimangono utili se compilate coi dati giusti e con un campione sufficientemente ampio. Per esempio nelle primarie ancora in corso la componente demografica dell’elettorato Democratico è servita a predire correttamente l’esito in diversi stati: in quelli a maggioranza bianca e meno popolati solitamente ha vinto Sanders, negli stati più etnicamente variegati e abitati ha vinto Clinton.
5. La vittoria di Trump non deve cambiare la nostra percezione
Nel 2011, quando ancora scriveva per il New York Times, Silver avvertì in un suo articolo di non sottovalutare Herman Cain, uno dei candidati più simili a Trump prima che arrivasse Trump. Ricorda Silver: «Tre giorni dopo che pubblicai quel pezzo, nell’ottobre 2001, Cain fu coinvolto in uno scandalo sessuale. Un mese dopo sospese la sua campagna. La convinzione comune aveva vinto: il vantaggio di Cain nei sondaggi si era rivelato una fregatura». Sbagliare una previsione del genere può avere conseguenze pericolose, conclude Silver:
Se facciamo un errore del genere – per esempio dando fiducia ai sondaggi che davano Cain in vantaggio – ci sentiamo scottati, e la volta successiva ci penseremo due volte prima di rifarlo. In questo modo però rischiamo di commettere l’errore opposto, per esempio dando scarso ascolto ai sondaggi nazionali del 2016 perché quelli del 2012 si rivelarono fallaci.
Di conseguenza, possiamo aspettarci che quando nel 2020 o nel 2024 arriverà il prossimo Trump il pensiero comune tenderà a sopravvalutarlo? È possibile che Trump cambi il Partito Repubblicano in maniera così radicale che il processo di nomination non sarà più lo stesso. Ma è anche possibile che la sua vittoria non abbia spostato le cose più di tanto: forse, semplicemente, una volta su dieci un partito trova il modo di mandare in vacca le cose scegliendo uno come Trump, o altri come lui.



