Salvati dagli errori
«Escludo che fra dieci anni mi manterrò traducendo, che è come mi sono mantenuto nei dieci anni passati. Non ho idea – non abbiamo idea, come società – di cosa accadrà a tutti i lavoratori resi ridondanti da questi sviluppi, come non la abbiamo avuta con la dismissione dell’industria pesante».


Due anni fa ho incontrato a una festa un gruppo di ricercatori che si occupavano di machine learning e intelligenza artificiale. Quando mi hanno chiesto cosa facevo io ho detto il traduttore letterario, suscitando imbarazzo e perplessità. «Wow», mi ha detto una di loro, con la sorpresa di chi incontra un animale esotico. «Non pensavo che fosse ancora qualcosa che fanno le persone».
Quella risposta, certo, rivela una certa ignoranza rispetto al settore in cui lavoro (del tutto comprensibile e peraltro simmetrica); ma mostra anche un’idea del futuro che è data per scontata da chi si occupa di machine learning e però risulta difficile da concepire – perché per molti versi letteralmente inconcepibile – per tutti gli altri. “La gente parla di Miami o del Bangladesh come se avessero ancora una chance,” diceva un famoso reportage sul cambiamento climatico il cui argomento era che non ce l’abbiano più, una chance. In modo simile, la gente parla di traduttori, di esperti di comunicazione, di avvocate civiliste, di autori.
Non sto dicendo che queste professioni spariranno, come non credo che Miami e il Bangladesh saranno espunti dalla crosta terrestre; ma si trasformeranno in modi che per ora ci risulta complicato persino immaginare. Da traduttore, forse ho cominciato la trasformazione un po’ prima di altri.
Da pochi giorni OpenAI ha messo online un chatbot basato sull’ultima versione di GPT-3, il modello linguistico più avanzato disponibile pubblicamente; e i social media e i giornali si sono popolati di esempi sorprendenti, profondi, spaventosi di cosa sia in grado di fare. Un modello linguistico è in sostanza un enorme macchinario statistico. Analizza miliardi di miliardi di parole (questo è il “learning” del “machine learning”), e calcola quanto è probabile che, data una certa serie, ne segua una anziché un’altra. Ad esempio: date le parole “ha messo online un chatbot basato sull’ultima”, versione è un seguito più probabile di iterazione che è più probabile di catastrofe che è più probabile di cavalluccio. Estendendo il processo ricorsivamente si arriva a generare testi formalmente corretti, pertinenti e spesso coerenti. Ovviamente è tutto molto, molto, molto più complicato di così, ma ai fini del nostro discorso questo basta.
È poco? No. Ad esempio, immaginate di avere queste parole: “Contratto di locazione a uso abitativo.” Oppure: “[Marchio] annuncia il lancio dell’innovativa serie di orologi [nome]”. Oppure: “In italiano, ‘the apple is on the table’ si traduce”. Gli sviluppi statisticamente più probabili di questi prompt sono, rispettivamente, un contratto, un comunicato stampa, e una traduzione.
Di che livello sono? Il primo prompt qui sopra, per esempio, produce un comunicato stampa di una pagina con tanto di descrizione dettagliata dei processi produttivi e intervista al CEO, che il sistema ha deciso essere milanese, come ha deciso che lo stile degli orologi è essenziale e ispirato al Bauhaus. In realtà non ha “deciso” niente: ha constatato che è più probabile che un marchio di orologi di lusso abbia sede a Milano che a Malmö. È altamente probabile che un comunicato stampa del genere contenga un’intervista. E così via. Ci sono esempi ovunque, e basta registrarsi gratuitamente sul sito di OpenAI per generarne di propri. I risultati non sono mai ottimi – ci sono sviste e incoerenze e imprecisioni – ma sono mediamente accettabili, e destinati a migliorare. Sono anche il risultato di pochi secondi di tempo e pochi centesimi di spesa, rispetto alle ore che ci metterebbe un umano. Per il momento, avere un modello linguistico non è come avere il genio della lampada: è come avere un esercito di schiavi tonti ma onniscienti e molto molto veloci.
Fatta la tara ai giochini già attivati – le spiegazioni di fisica nello stile di Gollum, le lezioni di programmazione nello slang dei mafiosi italoamericani – gli esempi più interessanti da studiare per capire cosa ci aspetta sono i testi in cui la probabilità risulta una guida efficace (cioè quelli che vengono bene a uno schiavo tonto ma onnisciente): i testi formulari e in qualche misura meccanici. I comunicati stampa, certo: ma anche i contratti e le traduzioni. Anche il codice di programmazione, peraltro: gli stessi responsabili dell’automazione rischiano di finire automatizzati.
Ma lo rischiano, lo rischiamo veramente? Per quanto sia a dir poco incredibile ciò che questi modelli sono in grado di fare, è ancora imperfetto: e in molti casi, un risultato imperfetto non basta. Nella traduzione di un romanzo, almeno per chi non ama i romanzi, fa poca differenza; ma quando si tratta di un contratto, o del manuale d’istruzioni di un elettrodomestico, o di un software, un singolo errore rende il tutto inutile o anche pericoloso.
Certo, la qualità è destinata a crescere – dal lancio dell’iterazione precedente di GPT, meno di un anno fa, il balzo è già stato impressionante – ma è importante rendersi conto che l’architettura stessa di questi sistemi rende la perfezione difficile da raggiungere. I modelli si formano su tutti i testi: il che significa anche su quelli sbagliati, che quindi rientreranno nel calcolo statistico degli esiti possibili. Ci sono meccanismi correttivi, ma è teoricamente improbabile e praticamente quasi impossibile che il margine di errore venga azzerato.
D’altro canto, anche al livello in cui sono ora, i modelli linguistici rendono certi compiti così rapidi e produttivi che un impatto violentissimo e vario sulle professioni sarà inevitabile. Quando faccio il cosiddetto “post-editing” – cioè traduco rivedendo una traduzione automatizzata, che oggi è piena di errori anche coi migliori sistemi – completo il doppio di pagine al giorno, a pari qualità. Quando parliamo di “automazione” pensiamo alle fabbriche e ai depositi Amazon: ma un braccio manipolatore in grado di sostituire un operaio costa decine o centinaia di migliaia di euro. Un sistema come GPT è scalabile senza limiti, al solo costo dell’elettricità. Certe professioni tecnico-intellettuali sono molto più a rischio di automazione delle attività manifatturiere.
Quello che accadrà di certo – che in molti casi è già accaduto – è che una singola professionista sarà in grado di produrre molto di più in molto meno tempo, che si tratti di comunicati stampa, traduzioni, o codice di programmazione; quindi le tariffe crolleranno; quindi i settori si ridurranno drasticamente. In qualche misura ciò permetterà di eliminare compiti ingrati e ripetitivi (per anni ho tradotto cataloghi commerciali: so di cosa parlo), ma quei compiti ingrati – ad esempio nel mio caso – permettevano di crescere professionalmente e ottenerne altri più gratificanti. Questo non accadrà più.
In molti casi ci sarà sempre bisogno di un essere umano a garantire la bontà del risultato; ma rivedere in cerca di contraddizioni e refusi l’output di una macchina è molto meno appagante e più alienante che non produrlo da sé. Non è solo una questione di ripetitività: c’è qualcosa di metafisicamente sconsolante nel sentirsi l’ultimo passaggio di una catena automatica, umano solo perché farlo fare a un robot costa troppo. Anni fa ho intervistato i lavoratori di un deposito Amazon appena automatizzato. Nonostante il lavoro fosse divenuto molto meno pericoloso e stressante – ora anziché correre per ore nel magazzino erano seduti a spostare cose fra scaffali semoventi – in molti soffrivano della trasformazione: si sentivano come al servizio delle macchine, che si presentavano a loro dicendo “prendi questo, sposta quello”, e poi se ne andavano, sostituiti dalla seguente. Sì, quando faccio post-editing sono veloce il doppio: ma dopo qualche giorno mi sento demotivato e triste, rancoroso. È un lavoro più rapido ma non è il lavoro che amavo. Anche questa trasformazione mi pare inevitabile e in parte già in corso.
Nei ragionamenti sull’automazione, questo è il punto in cui di solito si parla di distruzione creativa, di nuove opportunità per i lavoratori liberati, di riconversione. Non intendo parlarne. La riconversione più decantata dai sostenitori della distruzione creativa – programmare, il mestiere del futuro! – sarà una delle prime ad essere automatizzata, specie ai livelli banali a cui può arrivare chi ci giunge tardi e come ripiego. Escludo che fra dieci anni mi manterrò traducendo, che è come mi sono mantenuto nei dieci anni passati. Non ho idea – non abbiamo idea, come società – di cosa accadrà a tutti i lavoratori resi ridondanti da questi sviluppi, come non la abbiamo avuta con la dismissione dell’industria pesante. L’unica soluzione che trovo sensata – un reddito di base universale – non gode di buona reputazione, in Italia. La distruzione creativa è distruzione. Magari un giorno a Miami sorgeranno splendide città di palafitte collegate da passerelle aeree e hovercraft ad energia solare, ma questa idea non riconforta chi ci vive, oggi, negli edifici destinati a sprofondare.
E quindi? Nel ciclo dei robot, Isaac Asimov aveva immaginato un computer tanto intelligente da essere scelto dall’umanità intera come guida politica planetaria. Dopo un po’, misteriosamente, il computer comincia a sbagliare. I vari leader umani, impigriti dall’automazione, sono costretti a rimediare agli errori, che però non si spiegano: quel computer è per definizione perfetto. L’unica spiegazione, data da Asimov, era che tale sistema, appunto perché perfetto, aveva intuito che gli umani non dovevano impigrirsi, pianificando quindi apposta la propria obsolescenza per costringersi a ribellarsi. Nel preparare questo articolo, ho chiesto a ChatGPT di scrivermi una canzone sui traduttori resi ridondanti da GPT.
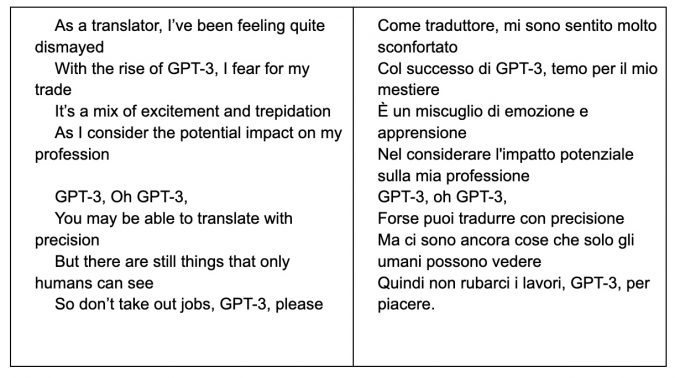
È immediato notare che nella versione inglese l’ultimo verso sarebbe molto meglio, a livello ritmico e di rima, se “GPT-3” fosse dopo “please”. Probabilmente è un errore da cui il sistema imparerà. La mia irragionevole speranza è che invece sia lì apposta perché vi sia ancora qualcosa che “solo gli umani possono vedere”.


