Perché non faccio grafici sulla pandemia
- Condividi
- X
- Regala il Post

Mi è stato chiesto da più parti come mai io non abbia fatto un’analisi matematica del contagio: l’unico mio post al riguardo è stato un mese e mezzo fa, dove mi sono limitato a dire di fare attenzione ai picchi, oltre ad avere scritto insieme ad Alberto Saracco una spiegazione su come funziona una crescita esponenziale. La ragione di questo mio silenzio è molto semplice, e si può riassumere in tre parole: “non avrebbe senso”. Quello che può però avere senso è spiegare meglio la mia reticenza.
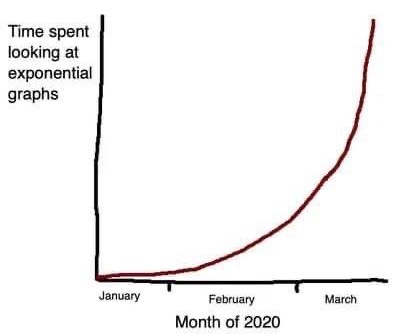
Grafico autoesplicativo (da https://bit.ly/3awwT0k )
In queste settimane le conferenze stampa delle 18 tenute dalla Protezione Civile sono più seguite delle puntate di Lascia o Raddoppia di sessant’anni fa. Poi naturalmente ci sono tutte le altre fonti mediatiche che cercano di anticipare oppure seguono a ruota – non ho ancora ben capito per esempio perché ilmeteo.it abbia tutte quelle tabelline colorate che mi trovo replicate su Facebook da parecchi miei contatti.
Un’infodemia di questo tipo ha un problema che sovrasta tutto il resto: diventa sempre più difficile capire quali sono i valori da confrontare. Un giorno mancano i dati di una regione; il giorno dopo cambia la procedura con cui si prendono i tamponi; il giorno dopo ancora i laboratori sono in ritardo.
Tanti punti fanno tante curve ( https://xkcd.com/2048/ )
È vero che chiunque sia abituato ad analizzare i dati sa che per esempio facendo una media mobile su qualche giorno quegli errori tipicamente si compensano, ma vedo tanta gente che si limita a prendere i valori e li dà in pasto a un qualche modello che tira automaticamente fuori la “migliore curva”. Il guaio è il modello è tutto fuorché stabile. Leggiamo per esempio quello che scrive Giovanni Organtini, che sta analizzando tutti i dati ricevuti:
Dall’analisi che faccio quotidianamente per predire il picco si evince che la data in cui questo sarà raggiunto si è spostata sempre piú in là col passare del tempo. Questo è del tutto ragionevole perché la crescita dei casi rallenta man mano che si assumono misure di contenimento via via piú efficaci. L’incapacità di predire con largo anticipo si può leggere come una buona notizia: le misure di contenimento tendono a spostare il picco a destra (ovviamente, abbassandolo).
Se quello che ci interessa è vedere se la situazione sta effettivamente migliorando, il fatto che ogni giorno il picco si sposti in là nel tempo è utile; ma se vogliamo sapere quando il picco ci sarà, fare i grafici non serve a molto. Beh, forse qualcuno davvero bravo potrebbe tirare fuori un meta-grafico studiando la variazione dei grafici col passare dei giorni, ma mi sembrerebbe un esercizio piuttosto campato in aria.
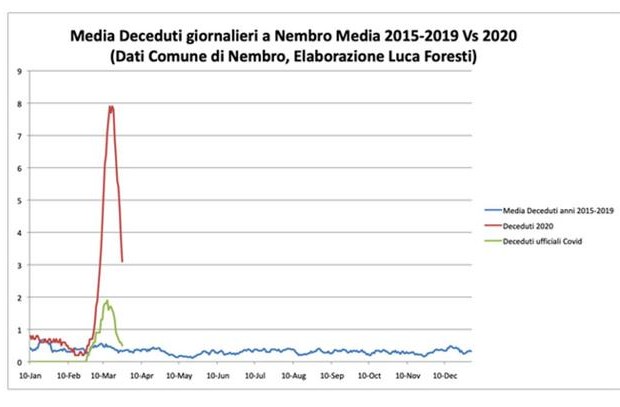
forse uno che sta male conta come 0,1 morti
In generale, come scrivevo, abbiamo però dati “sporchi”: non solo per gli errori di misurazione indicati sopra, ma anche e soprattutto perché mancano troppe informazioni. Probabilmente potremmo usare il numero di posti di terapia intensiva occupati dai malati, ricordandoci di prendere i dati veri e non quelli dei posti letto in genere; ma questi dati non tengono conto di chi si trova nelle case di riposo, se non addirittura a casa propria.
Un altro dato da cui si può avere un’idea di cosa succede è contare macabramente il numero di morti e confrontarlo con quello degli anni passati. Guardando i necrologi delle province di Bergamo e Brescia, dove attualmente ci sono i focolai maggiori, c’è chi ha stimato che i casi potrebbero essere quattro o cinque volte maggiori di quelli ufficiali – anche se io non mi fiderei molto di grafici dove il numero di morti ha oscillazioni frazionarie e preferisco analisi come questo studio di Matteo Villa, ricercatore dell’Ispi; non avremo dati precisi, ma perlomeno riusciamo a farci un’idea qualitativa di cosa sta succedendo.
Ma la vera ragione per cui tutti questi grafici lasciano il tempo che trovano è banalmente spazio-temporale. L’Italia ha avuto una serie di focolai distribuiti nel tempo, mentre per la maggior parte della nazione il lockdown è partito contemporaneamente. Questo significa che – se le misure prese sono state effettivamente sufficienti – stiamo mischiando nell’unico calderone dei dati nazionali numeri che appartengono a curve ben distinte.
Capite anche voi che ai calabresi importa poco sapere quale sia la situazione a Bergamo, e viceversa. Questo però non importa ai bulimici dei grafici, che prendono qualunque cosa passi il convento pur di fare previsioni destinate a priori a non essere rispettate. Spero insomma che mi perdonerete se non mi aggiungo alla pletora di coloro che non potendo parlare del campionato di calcio si sono riciclati in data analyst. Ad ogni modo, se proprio dovessi usare dei dati, prenderei semplicemente le infografiche dell’Istituto Superiore di Sanità, che con tutti gli avvertimenti del caso restano le più attendibili e hanno almeno una suddivisione in regioni: meglio che niente.


